In computer vision, 3D reconstruction aims to capture the shape and appearance of real objects. This process can be accomplished either by active or passive methods. Typically, passive methods only use an image sensor in a camera sensitive to visible light.
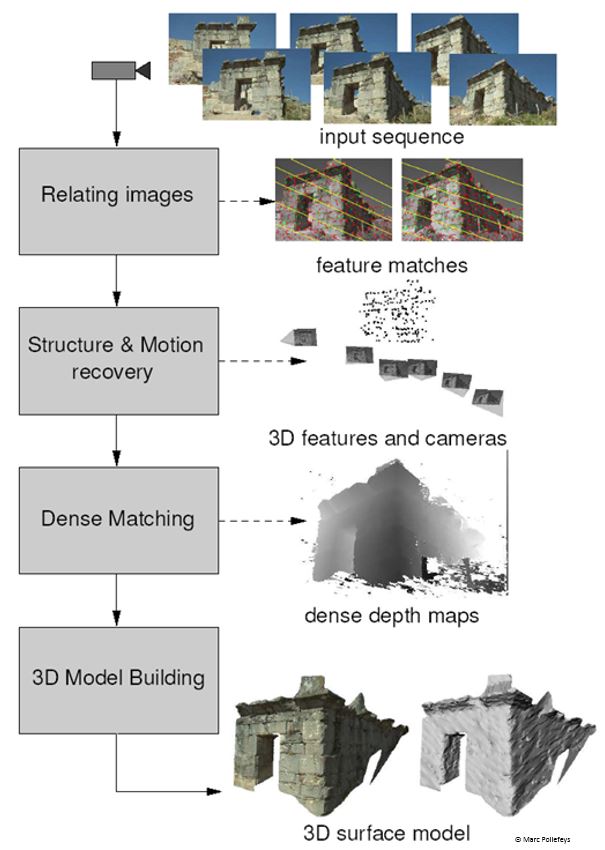
The process to extract 3D information begins with a set of digital images, and step by step it is possible to recover automatically all the information. First finding a few correspondences between images, relating the images each other, recovering the structure and motion, and finally calculate the per pixel depth information. The final result is a 3D model of the scene.
Instead, active methods interfere with the object to be reconstructed. These methods are being used in products such as Microsoft Kinect or Google Tango Project, where a known pattern is projected into the scene, providing more reliable depth information than passive methods for certain kind of object.
Combination of these methods can be used to 3D reconstruct a large variety of scenes.
 © DE5 LINEAR HOUSE SNC
© DE5 LINEAR HOUSE SNC
- 3D reconstruction
- Combination of active and passive methods
- More reliable information
 3D reconstruction © Marc Pollefeys
3D reconstruction © Marc Pollefeys
Report
3D capture
The acquisition of accurate and reliable 3D data is an essential step for the major goals of the Build2Spec project as it is required for novel inspection and progress tracking methods, as well as for quality check and management tools. The following report gives an overview of various acquisition methods and 3D scanning technologies that have been applied within the project. In particular, active depth sensing technologies like laser scanners, Google Tango tablet and Microsoft HoloLens devices have been used.